OD体育(中国) 首篇多模态大模子「音频推理」综述出炉, 万字拆解四大前一都径


设想这么一个闲适的周末: 空调带来阵阵凉意,你靠在沙发上看书,霎时耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵高昂、略带殷切的“呜呜”声,还伴跟着爪尖轻轻扒拉木门的声响。
淌若把这段音频丢进传统的语音大模子,它只会输出冷飕飕的三个字:[狗叫声]。AI 感知到了正确的音频信息,关联词全都错过了这段声息里包含的灵动与期待。
当模子仅仅把语音转成笔墨,它果真“听懂”了吗?
一个具备委果智能的多模态AI助手是什么样呢?它当先要能听出小狗的声息,然后捕捉到音频里的空间感(门边传来的声息)、序列动作(碎步声和握门声),并联接热诚(殷切的“呜呜”声),快速完成一系列逻辑推演,用欢笑的语调提醒你:“狗狗想外出漫衍啦,快带它出去玩吧!”
让AI从“冷飕飕地转录声息”到“大要听懂生存中的热诚、物理学问与逻辑”,这恰是大模子社区正在资历的一场巨变:从现存的“音频感知(Audio Perception)”全面进化到“音频推理(Audio Reasoning)”。这亦然大模子委果通向 AGI,成为咱们生存助手的必经之路!
关联词,当交互的模态从笔墨和图像转向声息,一个问题浮出水面:AI 能否不依赖转录的文本,平直基于声息进行推理?
这并不是一个技巧细节问题。委果全国里的声息,远不仅仅承载笔墨实质的载体。讲话东谈主的语气、语速、重音、停顿、热诚、多东谈主重迭讲话、环境事件等,都可能窜改推表面断。而浅薄残酷地把音频转写成笔墨,同样会丢失这些关节信息。
音频推理不应该仅仅文本或视觉推理的浅薄搬动,而是行为多模态基础模子中的幽闲问题从头界说。
近日,香港中语大学团队结伙多位优秀筹商者,追究推出了音频推理领域的首篇全景综述。本文初次全面界说了“音频推理”的范式,系统解构了底层框架,并深度剖析了刻下最受关爱的四大前沿推理旅途。

论文标题:
A Survey of Audio Reasoning in Multimodal Foundation Models
尊龙凯时2026世界杯中国官网论文延续:
https://arxiv.org/abs/2605.21008
本文系统整理了多模态基础模子中的音频推理筹商,提议调处的问题表述与分类框架,将刻下责任分为四条干线:Audio-to-Text Reasoning、Audio-to-Speech Reasoning、Audio-Visual Reasoning、Agentic Audio Reasoning,并进一步转头模子基础、数据构造、评测体系、挑战与昔日处所。
更紧要的是,本文强调了一个常常被漠视但极其关节的不雅点:音频推理的中枢不是“让模子说出一段推理链”,而是让推理过程委果锚定在一语气、细粒度、时候密集的声学左证上。
从“听清”到“听懂”,再到“推理决策”——这不仅仅刻下大模子才略提高的必经之路,更是通往 AGI 的关节一环。
从感知到推理:
为什么咱们需要 Audio Reasoning?
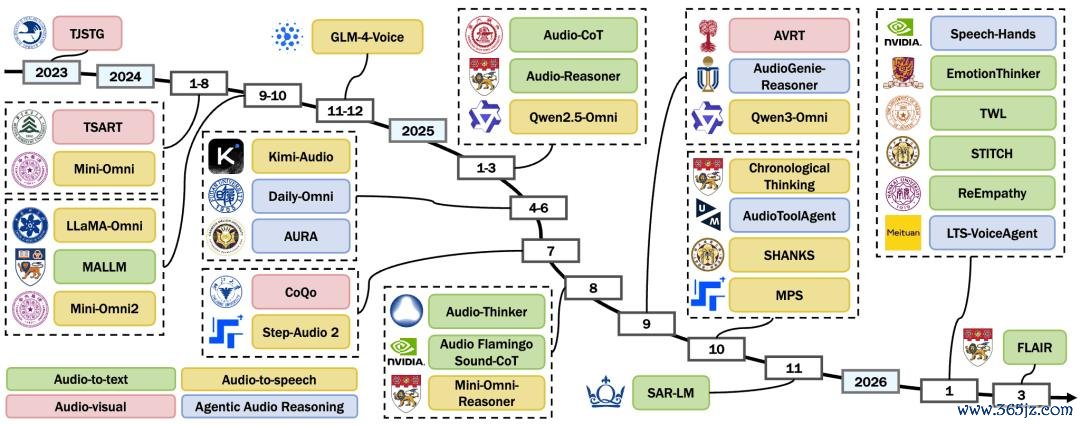
2023-2026 年,Qwen-Omni、Audio-Reasoner、Step-Audio、AudioToolAgent 等责任接踵推出,音频推理正在从碎屑化探索,缓缓走向体系化。
多模态大模子还是从“看图讲话”到“听、看、说、行动”的一体化系统。但刻下筹商责任仍存在赫然断层:
1、现存综述平淡关爱音频大模子、音频麇集、及时语音交互或多模态 CoT,而很少把“audio reasoning”行为中心问题单独张开。
2、音频推理仍处在高度零碎阶段:不同责任分歧筹商音频问答、语音交互、音视频推理、用具调用、评测基准,仍阑珊一个调处的框架来解释它们之间的联系。
3、许多所谓“音频推理”任务并不委果依赖音频。部分模子不错只依赖文本领导或音频转录得到正确谜底,这使得咱们必须从头谛视:模子是否果真在听声息?
因此,这篇综述进一步回答三个更根柢的问题:
什么是音频推理?它与平淡音频麇集有什么区别?
什么样的模子结构和老师格式能力完结委果的 acoustic-grounded reasoning?
怎么评估模子委果使用了声息行为左证,而不是在走文本捷径?
深层剖析音频推理四大范式
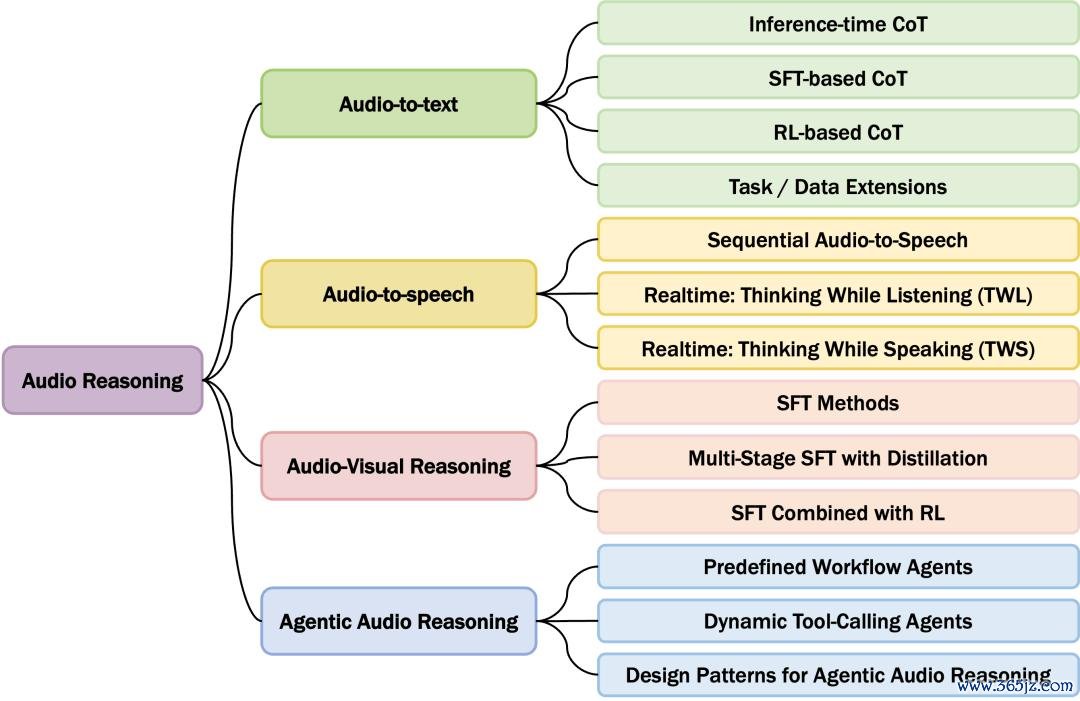
多模态大模辅音频推理才略的全景分类框架
本文初次提议一个全新的音频推理分类框架,多维度瓦解了现存前沿音频推理模子的中枢架构和指示微调计谋,为该领域筹商者提供了一份明晰的“技巧舆图”和“避坑指南”。要点剖析了四大前沿处所:
Audio-to-Text:卓绝转录的深层语义瓦解
刻下大模子在纯文本推理上阐扬惊艳,OD体育全站app下载但如安在采纳音频输入时幸免信息折损?本文详确探讨了模子在清寒显式文本领导的情况下,怎么平直从音频信号中索求逻辑链条,完成深层多步推理,并冲突长音频高下文麇集的瓶颈。接洽方法包括 inference-time CoT、SFT-based CoT 和 RL-based CoT。值得扎眼的是,本文筹商了一个反直观问题:CoT 在音频中并不老是灵验。一些筹商发现,CoT 对浅薄任务有匡助,但在繁重上却有可能误导模子;致使一些音频问答大要在不听音频的情况下依靠文本踪影猜对谜底。这种时势评释,委果的挑战不是让模子输出 ,而是让推理过程诞生在委果的声学左证上。
Audio-to-Speech:端到端的声学逻辑构建
委果的智能对话不可只输出冰冷的笔墨。本部分聚焦于端到端交互系统,探讨模子如安在生谚语音回话的同期,依然保留输入端的情谊共识以及副语言特征,并完成复杂的声学逻辑推理(举例:听出对方的反讽语气并作念出相应的反击)。传统 sequential 模式是“先听—再想—再说”,诚然逻辑齐备但延长性高。近期责任为缩小用户恭候时候,提议两类及时范式:在用户讲话时同步推理(Thinking While Listening);以及左右音频播放时候,瞻望算后续的推理和语音(Thinking While Speaking)。中枢问题是如安在推理的深度和低延长之间赢得均衡。
Audio-Visual Reasoning:同期听和看,跨模态推理
听觉与视觉的结伙推理是多模态领域的硬骨头。本文深度剖析了音视频结伙推理的前沿管制决策,揭示了怎么破解复杂场景下,声息源和视觉对象的跨模态空间与时候对都繁重。它不仅关爱讲话东谈主包摄,还关爱音画同步、事件定位、跨模态消歧等任务。与浅薄拼接音频转录文本和视觉特征不同,委果的音视频推理,需要模子在时候轴上对都两种一语气信号,并判断不同模态间的左证怎么互补或冲突。
Agentic Audio Reasoning:把音频推理扩张为智能体责任流
让模子学会“听指示行事”。该处所探讨了音频驱动的自主决策机制,深度剖析 Audio Agent 如安在委果物理或臆造环境中,通过听觉信息感知气象和接洽任务,并拓宽 Action 的履行鸿沟。复杂任务同样不可靠单一模子一次性回答,需要感知、接洽、用具调用、操心、考据和反想等措施合营。论文转头了两类道路:一类是固定经由的 predefined workflow agents,另一类是由 LLM planner 动态遴荐 ASR、TTS、搜索、邮件、日期等用具的 dynamic tool-calling agents。
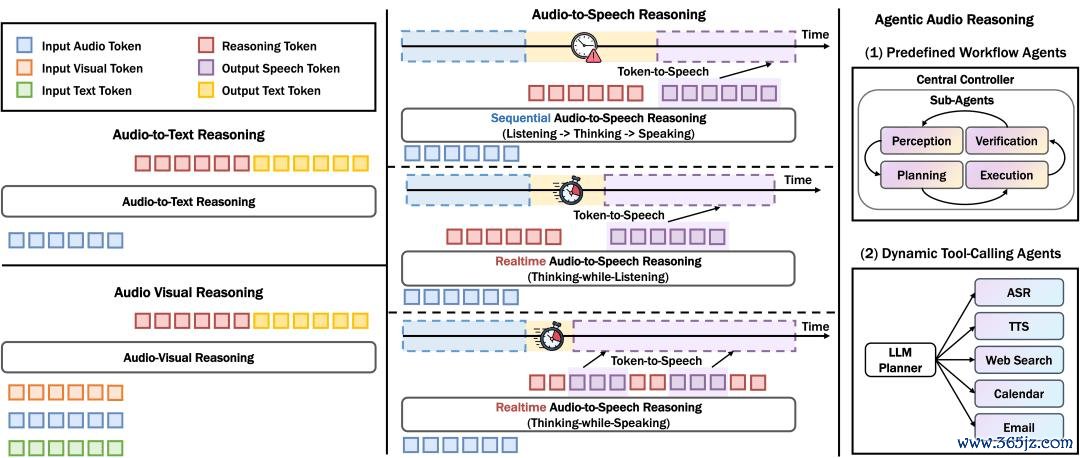
音频推理的主要范式
数据与评测:不可只看谜底对不合
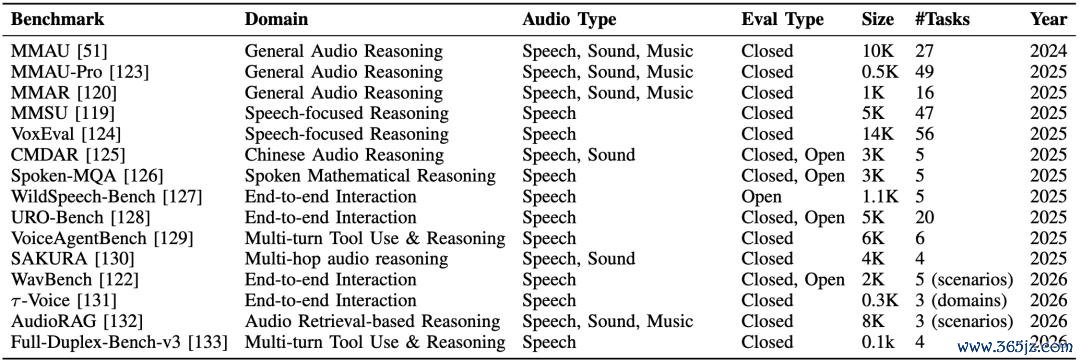
音频推理 Benchmark对比汇总
音频推理的出路宏大,但数据构造仍是繁重。刻下大鸿沟老师数据主要来自 MMAU、VoxEval等,再由大模子构造 QA 和推理链。一些责任使用 LLM-ALM ,进一步通过协同生成、自蒸馏,或引入语速、音高、重音等声学特征,减少文本幻觉和捷径学习。
论文指出:评测音频推理才略,不可只看最终谜底准确率,更紧要的是判断模子是否委果使用了音频行为依据。昔日 benchmark 需要减少文本捷径,掩饰语气、热诚、环境声、讲话东谈主、及时交互、长音频高下文和音视频 grounding 等更委果场景。
指路昔日:筹商热门在那儿?
关于想要入局“音频推理”的筹商者,著述在扫尾给出了极具价值的昔日趋势指路:合成的音频推理数据是否可靠;模子是否存在模态幻觉和 text-surrogate reasoning;在及时语音交互中怎么均衡准确性与低延长;播客、长会议以及环境灌音中的长高下文推理怎么完结;音频推理才略是否能从 post-training 前移到预老师或 mid-training 阶段。
结语
传统的语音系统只关爱“把声息转成笔墨”,而今天,委果交互、具身智能和多模态 agent场景,垂死需要下一代模子麇集声息中的意图、热诚、因果和高下文。
这篇综述初次将 Audio Reasoning 行为幽闲筹商对象系统张开,从神色化界说到模子基础,从 CoT、SFT、RL 到及时语音推理,从音视频 grounding 到 agentic workflow,再到评测与昔日处所。
昔日的 AI 不应仅仅“听见”声息OD体育(中国),而要委果启动“听懂并想考”。
 备案号:
备案号: